Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
*Equal contribution
*Equal contribution
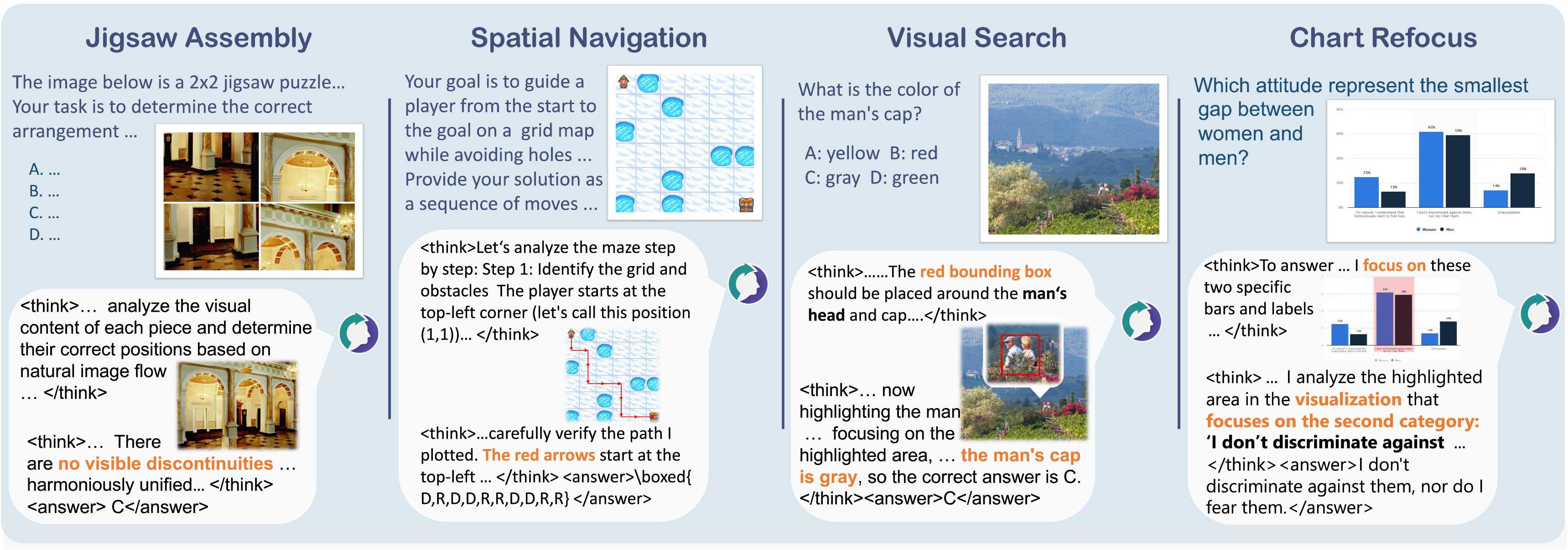
Multimodal reasoning requires iterative coordination between language and vision, yet it remains unclear what constitutes a meaningful interleaved chain of thought. We posit that text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning.
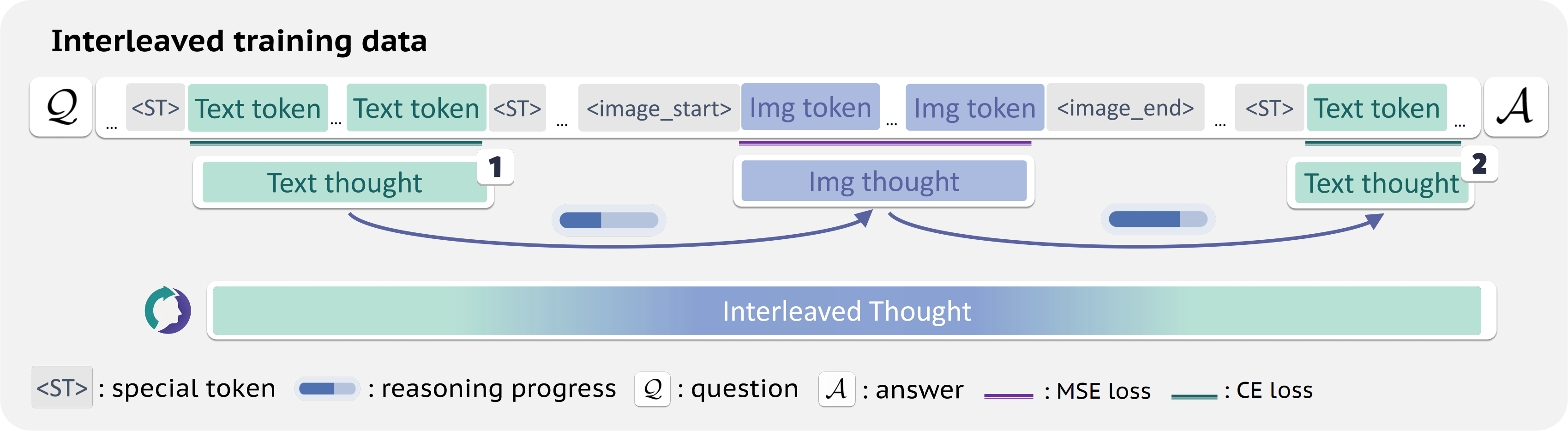
Guided by this principle, we build ThinkMorph, a unified model fine-tuned on ~24K high-quality interleaved reasoning traces spanning tasks with varying visual engagement. ThinkMorph learns to generate progressive text–image reasoning steps that concretely manipulate visual content while maintaining coherent verbal logic. It delivers large gains on vision-centric benchmarks (averaging 34.7% over the base model) and generalizes to out-of-domain tasks, matching or surpassing larger and proprietary VLMs. Beyond performance, ThinkMorph exhibits emergent multimodal intelligence, including unseen visual manipulation skills, adaptive switching between reasoning modes, and better test-time scaling through diversified multimodal thoughts. These findings suggest promising directions for characterizing the emergent capabilities of unified models for multimodal reasoning.
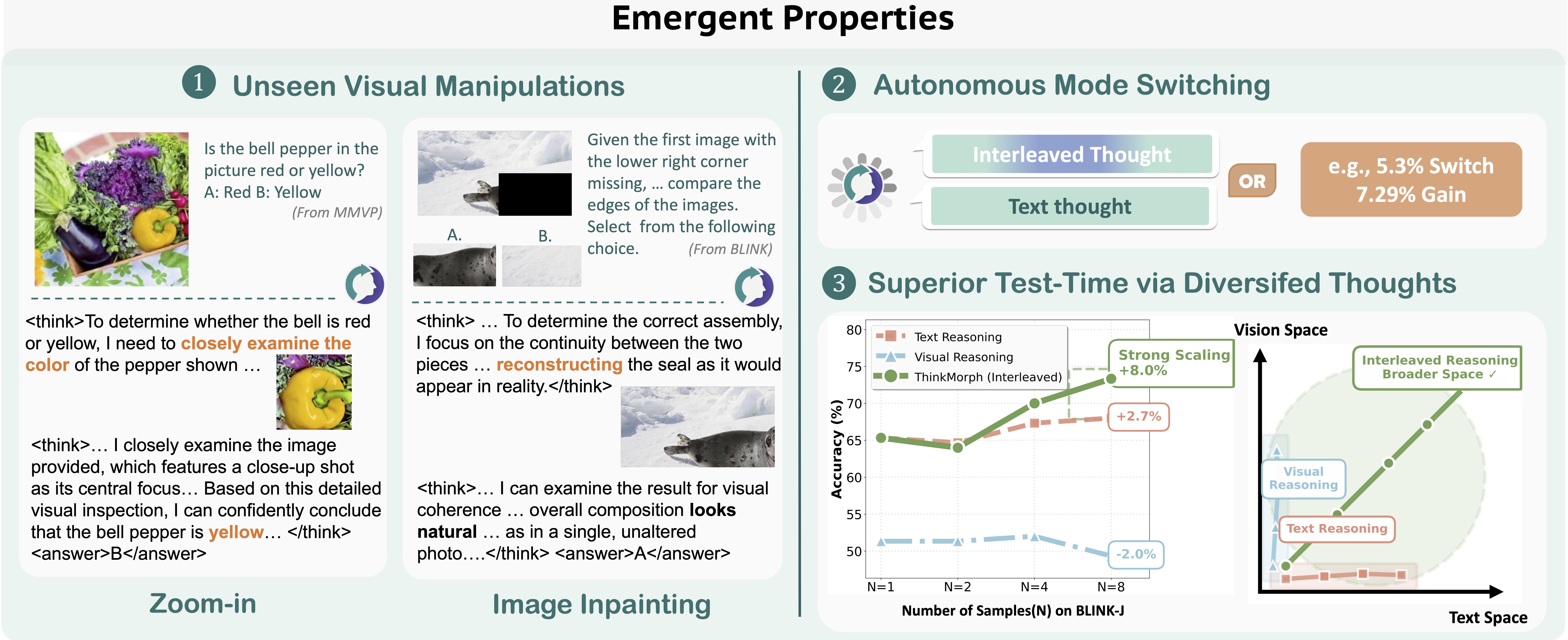
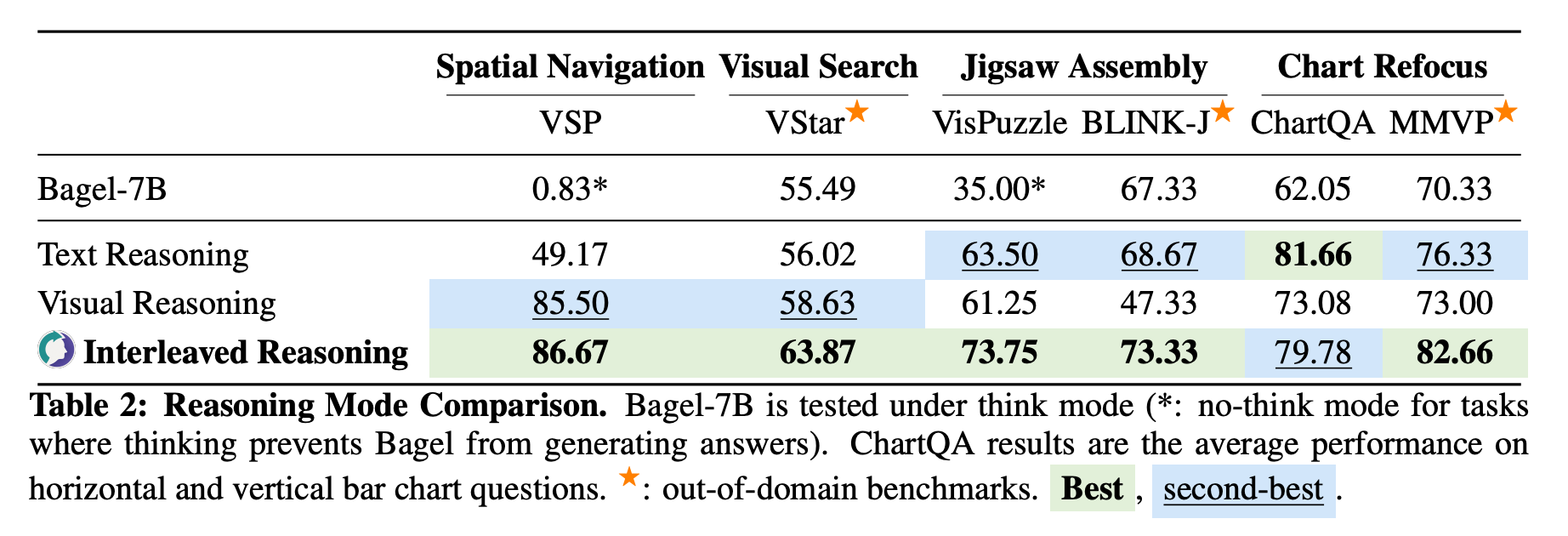
Reasoning Mode Comparison. ThinkMorph achieves substantial gains on vision-centric tasks, averaging a 34.74% improvement over its base model, with striking increases of 85.84% on Spatial Navigation and 38.75% on Jigsaw Assembly. Compared across reasoning modes, ThinkMorph's interleaved reasoning consistently outperforms text-only and vision-only approaches by 5.33%.
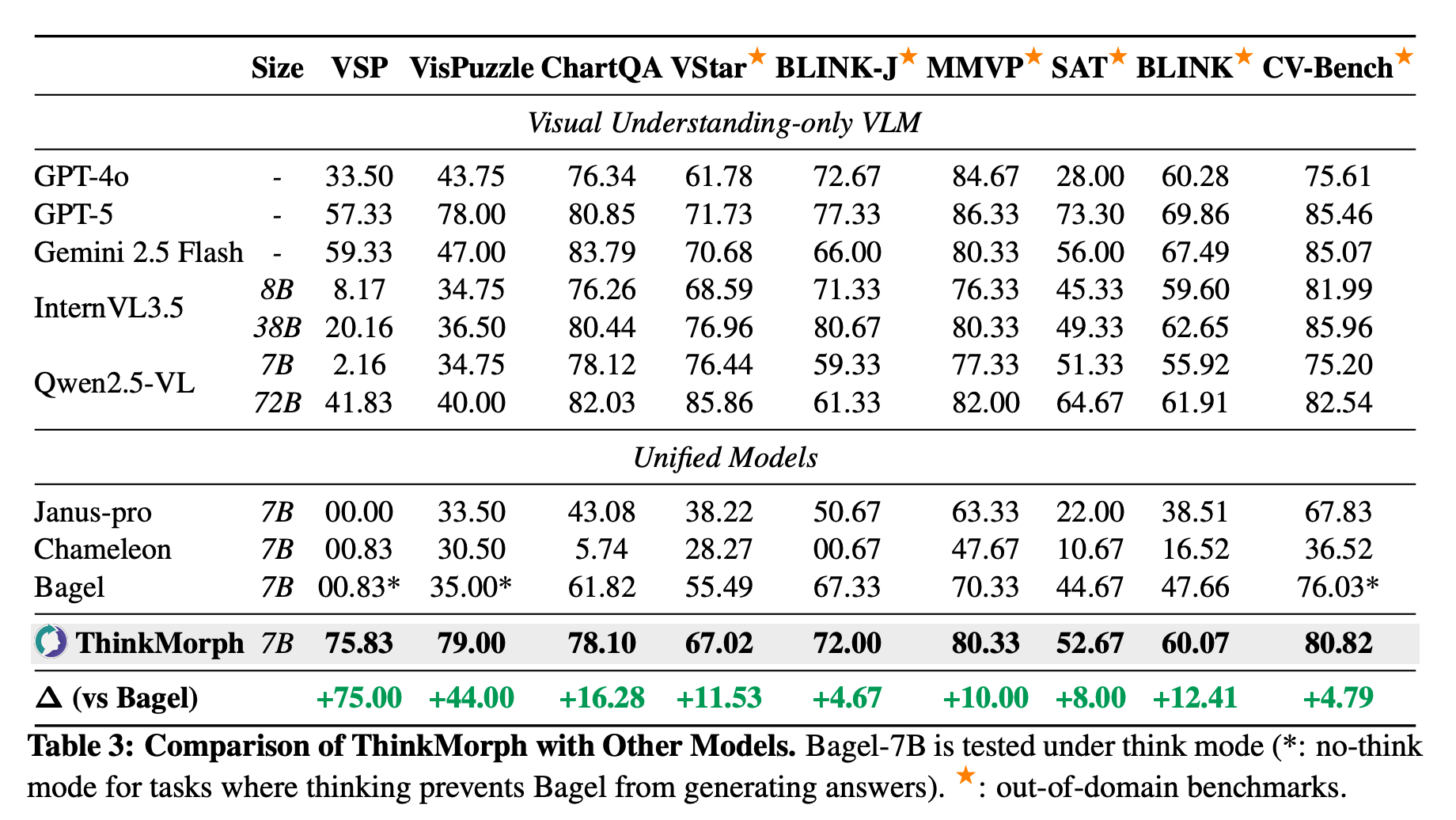
Comparison with State-of-the-Art VLMs. Compared to its base model, Bagel-7B, ThinkMorph achieves significant improvements across all benchmarks, with an average gain of 20.74% over nine diverse tasks. Despite being fine-tuned on only 24K samples, ThinkMorph achieves performance comparable to, and in several cases exceeding, models an order of magnitude larger: it outperforms Qwen2.5-VL-72B by 34% on VSP and 10.67% on BLINK-J, surpasses InternVL3.5-38B on SAT, and matches Gemini 2.5 Flash on general perception in MMVP (80.33%).
Explore more analysis of ThinkMorph's behaviors. For detailed discussions, please refer to our paper.
Click on any case to view detailed reasoning traces
@article{gu2025thinkmorph,
title={ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning},
author={Gu, Jiawei and Hao, Yunzhuo and Wang, Huichen Will and Li, Linjie and Shieh, Michael Qizhe and Choi, Yejin and Krishna, Ranjay and Cheng, Yu},
journal={arXiv preprint arXiv:2510.27492},
year={2025}
}